ForkJoinPool可以将大任务分解为小任务执行(多线程),并且能够获得小任务的返回结果,最终合并为结果集。
1. ForkJoinPool 是什么
ForkJoinPool 是自 java7 开始,jvm 提供的一个用于并行执行的任务框架。其主旨是将大任务分成若干小任务,之后再并行对这些小任务进行计算,最终汇总这些任务的结果。得到最终的结果。其广泛用在 java8 的 stream 中。 这个描述实际上比较接近于单机版的 map-reduce。都是采用了分治算法,将大的任务拆分到可执行的任务,之后并行执行,最终合并结果集。区别就在于 ForkJoin 机制可能只能在单个 jvm 上运行,而 map-reduce 则是在集群上执行。此外,ForkJoinPool 采取工作窃取算法,以避免工作线程由于拆分了任务之后的 join 等待过程。这样处于空闲的工作线程将从其他工作线程的队列中主动去窃取任务来执行。这里涉及到的两个基本知识点是分治法和工作窃取。
1.1 分治法
分治法的基本思想是将一个规模为 N 的问题分解为 K 个规模较小的子问题,这些子问题的相互独立且与原问题的性质相同,求出子问题的解之后,将这些解合并,就可以得到原有问题的解。是一种分目标完成的程序算法。简单的问题,可以用二分法来完成。 二分法,就是我们之前在检索的时候经常用到的 Binary Search 。这样可以迅速将时间复杂度从 O (n) 降低到 O (log n)。那么对应到 ForkJoinPool 对问题的处理也如此。基本原理如下图:
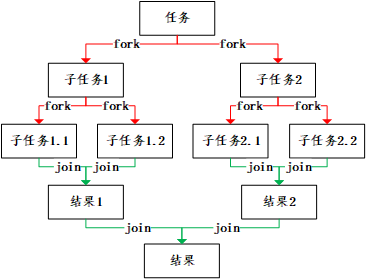
这只是一个简化版本的 Fork-Join,实际上我们在日常工作中的应用可能比这要复杂很多。但是基本原理类似。这样就将一个大的任务,通过 fork 方法不断拆解,直到能够计算为止,之后,再将这些结果用 join 合并。这样逐次递归,就得到了我们想要的结果。这就是再 ForkJoinPool 中的分治法。
1.2 工作窃取(work-stealing)
工作窃取是指当某个线程的任务队列中没有可执行任务的时候,从其他线程的任务队列中窃取任务来执行,以充分利用工作线程的计算能力,减少线程由于获取不到任务而造成的空闲浪费。在 ForkJoinpool 中,工作任务的队列都采用双端队列 Deque 容器。我们知道,在通常使用队列的过程中,我们都在队尾插入,而在队头消费以实现 FIFO。而为了实现工作窃取。一般我们会改成工作线程在工作队列上 LIFO, 而窃取其他线程的任务的时候,从队列头部取获取。示意图如下:
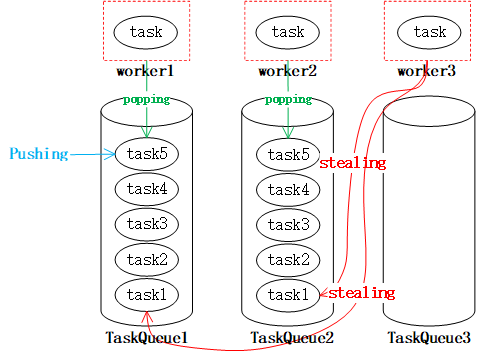
工作线程 worker1、worker2 以及 worker3 都从 taskQueue 的尾部 popping 获取 task,而任务也从尾部 Pushing,当 worker3 队列中没有任务的时候,就会从其他线程的队列中取 stealing,这样就使得 worker3 不会由于没有任务而空闲。这就是工作窃取算法的基本原理。 可以想象,要是不使用工作窃取算法,那么我们在不断 fork 的过程中,可能某些 worker 就会一直处于 join 的等待中。工作窃取的思想,实际实在 golang 协程的底层处理中也是如此。
2. 简单使用
在弄清楚了 fork-join 是什么了之后,我们来看看 JUC 中为我们提供的 forkjoin 是如何工作的。 在 juc 中,实现 Fork-join 框架有两个类,分别是 ForkJoinPool 以及提交的任务抽象类 ForkJoinTask。对于 ForkJoinTask,虽然有很多子类,但是我们在基本的使用中都是使用了带返回值的 RecursiveTask 和不带返回值的 RecursiveAction 类。
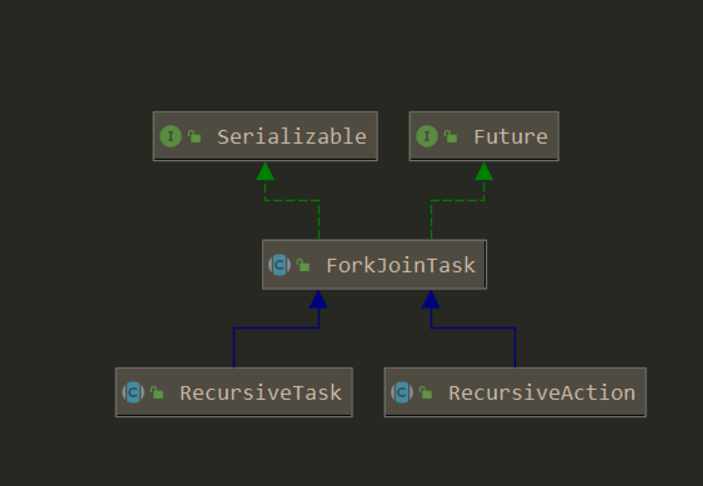
我们通过继承这两个类来实现两种类型的计算。
2.1 不带返回值的计算
RecursiveAction 可以实现不带返回值的 fork-join 计算。实现如下:
1 | package com.dhb.forkjoinpool; |
再执行如下 main 方法:
1 | import java.util.concurrent.ForkJoinPool; |
上述代码执行:
1 | ForkJoinPool-1-worker-1,i=1 |
可以看到上述线程将 1-50 并行的 print 出来。
2.2 带返回值的计算
通过实现 RecursiveTask 来进行带有返回值的计算。如我们需要计算 1-1000000 的累加结果。实现如下:
1 | package com.dhb.forkjoinpool; |
主函数如下:
1 | import java.util.concurrent.ForkJoinPool; |
上述代码执行结果:
1 | 循环计算 1-1000000 累加值:1784293664 |
这样就非常容易的实现了一个基于并行的计算。