在 Java 领域,定时任务框架主要有Spring Schedule、Quartz、xxl-job。
一般简单的,且不需要动态管理的定时任务,使用@Scheduled注解即可;在需要动态维护定时任务的单体应用场景中,一般使用Quartz;在分布式定时任务动态维护场景中,一般使用xxl-job。
下文主要介绍Quartz
对比
在 Java 领域,有很多定时任务框架,这里简单对比一下目前比较流行的三款:

网络资源:
- Quartz 文档:https://www.w3cschool.cn/quartz_doc/
- xxl-job 博客:https://www.cnblogs.com/xuxueli/p/5021979.html
本文框架
本文主要有以下内容:
- Quartz 的基本认知和源码初探
- Quartz 的基本使用
- Quartz 的进阶使用,包括 Job 中注入 Mapper 层、Quartz 的持久化
初识 Quartz
如果你的定时任务没有分布式需求,但需要对任务有一定的动态管理,例如任务的启动、暂停、恢复、停止和触发时间修改,那么 Quartz 非常适合你。
Quartz 是 Java 定时任务领域一个非常优秀的框架,由 OpenSymphony(一个开源组织)开发,这个框架进行了优良地解耦设计,整个模块可以分为三大部分:
- Job:顾名思义,指待定时执行的具体工作内容;
- Trigger:触发器,指定运行参数,包括运行次数、运行开始时间和技术时间、运行时长等;
- Scheduler:调度器,将 Job 和 Trigger 组装起来,使定时任务被真正执行;
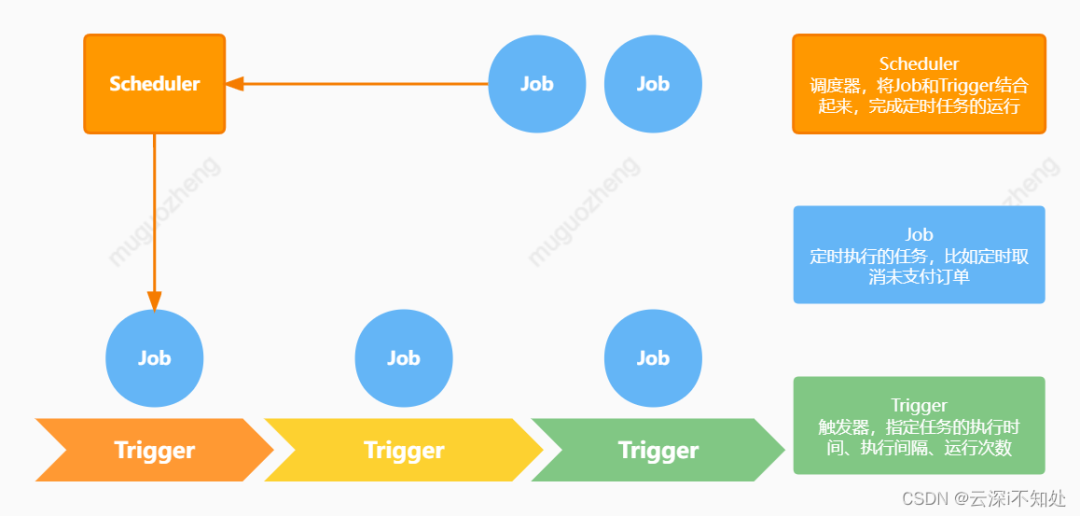
下面这个图简略地描述了三者之间的关系:
- 一个 JobDetail(Job 的实现类)可以绑定多个 Trigger,但一个 Trigger 只能绑定一个 JobDetail;
- 每个 JobDetail 和 Trigger 通过 group 和 name 来标识唯一性;
- 一个 Scheduler 可以调度多组 JobDetail 和 Trigger。
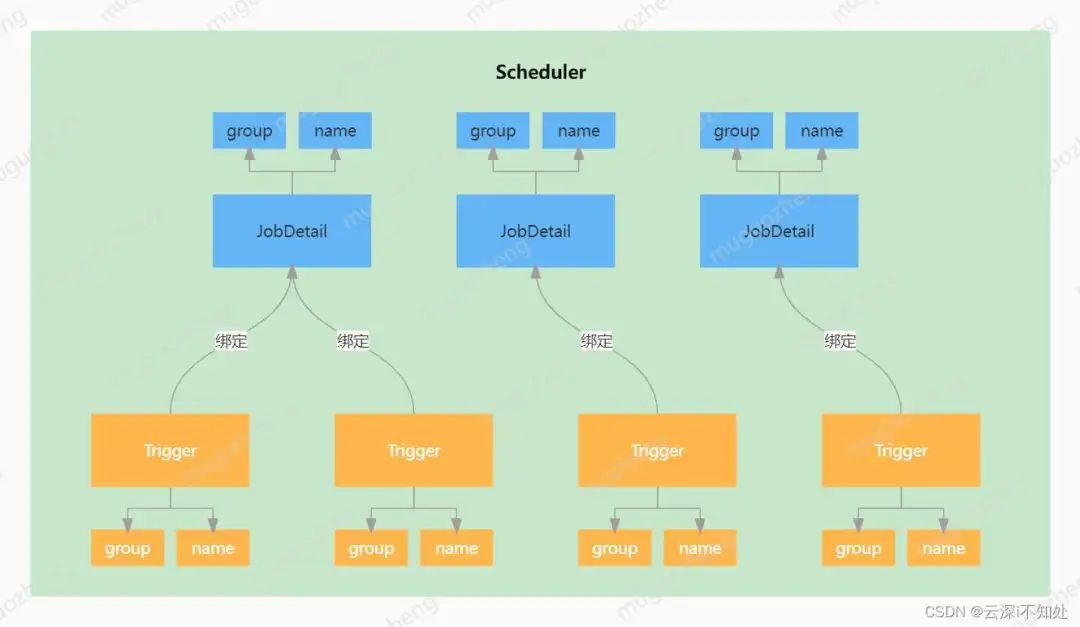
为了便于理解和记忆,可以把这套设计机制与工厂车间相关联:
- Job:把 Job 比作车间要生产的一类产品,例如汽车、电脑等。
- Trigger:trigger 可以理解为一条生产线,一条生产线只能生产一类产品,但一类产品可以由多条生产线生产。
- Scheduler:Scheduler 则可以理解为车间主任,指挥调度着车间内的生产任务(Scheduler 内置线程池,线程池内的工作线程即为车间工人,每个工人承担着一组任务的真正执行)。
Quartz 基础使用
Quartz 提供了丰富的 API,下面我们在 Springboot 中使用 Quartz 完成一些简单的 demo。
基于时间间隔的定时任务
基于时间间隔和时间长度实现定时任务,借助 SimpleTrigger,例如这个场景 —— 每隔 2s 在控制台输出线程名和当前时间,持续 30s。
1. 导入依赖:
1 | <dependency> |
2. 新建 Job,实现我们想要定时执行的任务:
1 | public class SimpleJob implements Job { |
3. 创建 Scheduler 和 Trigger,执行定时任务:
1 | public class SimpleQuartzTest { |
启动测试方法后,控制台观察现象即可。注意到这么一句日志:Using thread pool ‘org.quartz.simpl.SimpleThreadPool’ - with 10 threads.,这说明 Scheduler 确实是内置了 10 个线程的线程池,通过打印线程名也印证了这一点。
另外要尤其注意的是,我们之所以通过 TimeUnit.SECONDS.sleep (30); 设置休眠,是因为定时任务是交由线程池异步执行的,而测试方法运行结束,主线程随之结束导致定时任务也不再执行了,所以需要设置休眠 hold 住主线程。在真实项目中,项目的进程是一直存活的,因此不需要设置休眠时间。
这其中的区别可以参考:https://github.com/ThinkMugz/springboot-demo-major。
基于 Cron 表达式的定时任务
基于 Cron 表达式的定时任务 demo 如下:
1 | public class SimpleQuartzTest { |
Quartz 解读
整个 Quartz 体系涉及的类及之间的关系如下图所示:
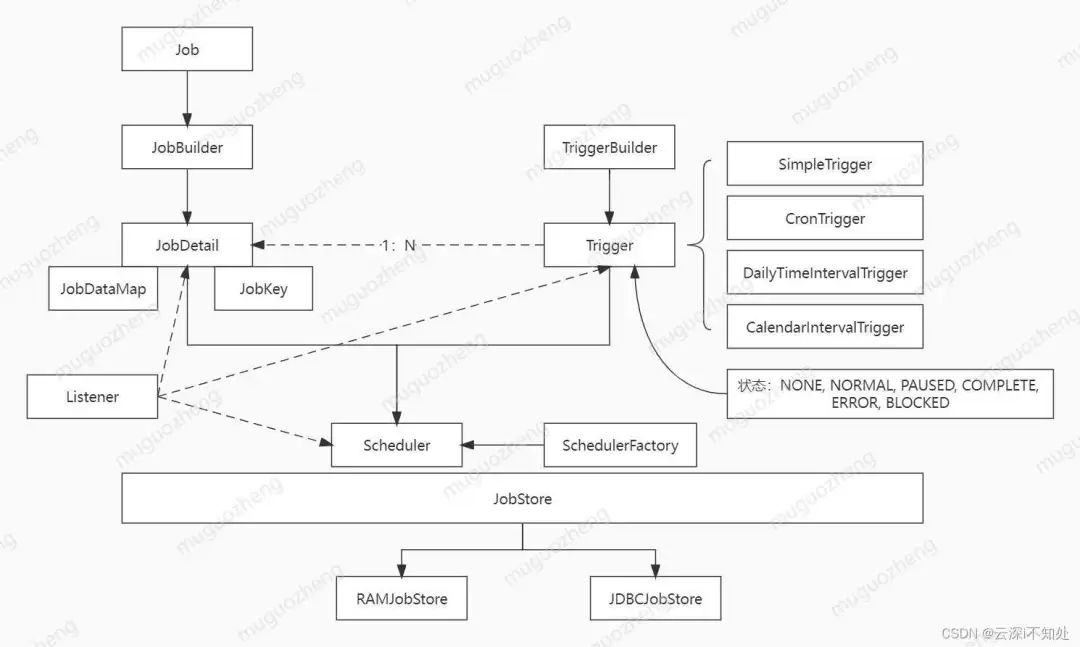
- JobDetail:Job 接口的实现类,由 JobBuilder 将具体定义任务的类包装而成。
- Trigger:触发器,定义定时任务的触发规则,包括执行间隔、时长等,使用 TriggerBuilder 创建,JobDetail 和 Trigger 可以一对多,反之不可。触发器可以拥有多种状态。
- Scheduler:调度器,将 Job 和 Trigger 组装起来,使定时任务被真正执行;是 Quartz 的核心,提供了大量 API。
- JobDataMap:集成 Map,通过键值对为 JobDetail 存储一些额外信息。
- JobStore:用来存储任务和触发器相关的信息,例如任务名称、数量、状态等等。Quartz 中有两种存储任务的方式,一种在在内存(RAMJobStore),一种是在数据库(JDBCJobStore)。
Job
Job 是一个接口,只有一个方法 execute (),我们创建具体的任务类时要继承 Job 并重写 execute () 方法,使用 JobBuilder 将具体任务类包装成一个 JobDetail(使用了建造者模式)交给 Scheduler 管理。每个 JobDetail 由 name 和 group 作为其唯一身份标识。
JobDataMap 中可以包含不限量的(序列化的)数据对象,在 job 实例执行的时候,可以使用其中的数据。
JobDataMap 继承 Map,可通过键值对为 JobDetail 存储一些额外信息。
Trigger
Trigger 有四类实现,分别如下:
- SimpleTrigger:简单触发器,支持定义任务执行的间隔时间,执行次数的规则有两种,一是定义重复次数,二是定义开始时间和结束时间。如果同时设置了结束时间与重复次数,先结束的会覆盖后结束的,以先结束的为准。
- CronTrigger:基于 Cron 表达式的触发器。
- CalendarIntervalTrigger:基于日历的触发器,比简单触发器更多时间单位,且能智能区分大小月和平闰年。
- DailyTimeIntervalTrigger:基于日期的触发器,如每天的某个时间段。
Trigger 是有状态的:NONE, NORMAL, PAUSED, COMPLETE, ERROR, BLOCKED,状态之间转换关系:
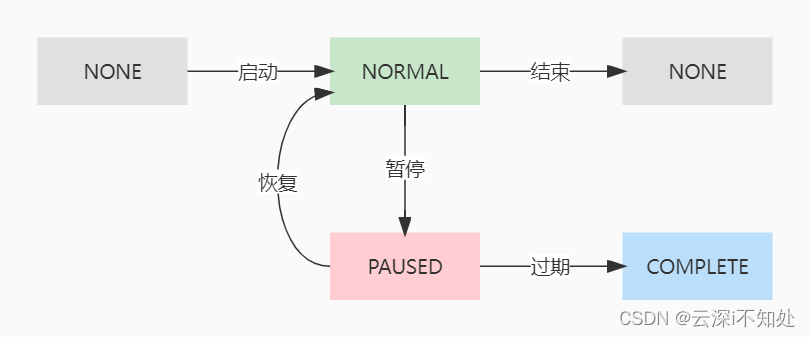
COMPLETE 状态比较特殊,我在实际操作中发现,当 Trigger 长时间暂停后(具体时长不太确定)再恢复,状态就会变为 COMPLETE,这种状态下无法再次启动该触发器。
Scheduler
调度器,是 Quartz 的指挥官,由 StdSchedulerFactory 产生,它是单例的。Scheduler 中提供了 Quartz 中最重要的 API,默认是实现类是 StdScheduler。
Scheduler 中主要的 API 大概分为三种:
- 操作 Scheduler 本身:例如 start、shutdown 等;
- 操作 Job:例如:addJob、pauseJob、pauseJobs、resumeJob、resumeJobs、getJobKeys、getJobDetail 等
- 操作 Trigger:例如 pauseTrigger、resumeTrigger 等
这些 API 使用非常简单,源码中也有完善的注释,这里不再赘述。
Quartz 进阶使用
除了基本使用外,Quartz 还有一些较为复杂的应用场景。
多触发器的定时任务
前文提过,一个 JobDetail 可以绑定多个触发器,这种场景还是有一些注意点的:
- 首先,要通过 storeDurably () 方法将 JobDetail 设置为孤立后保存存储(没有触发器指向该作业的情况);
- Scheduler 通过 addJob () 将给定的作业添加到计划程序中 - 没有关联的触发器。作业将处于 “休眠” 状态,直到使用触发器或调度程序对其进行调度;
- 触发器通过 forJob (JobDetail jobDetail) 指定要绑定的 JobDetail,scheduleJob () 方法只传入触发器,触发后将自动执行 addJob 过的绑定 JobDetail。
1 | public class MultiQuartzTest { |
Job 中注入 Bean
有时候,我们要在定时任务中操作数据库,但 Job 中无法直接注入数据层,解决这种问题,有两种解决方案。
方案一:借助 JobDataMap
在构建 JobDetail 时,可以将数据放入 JobDataMap,基本类型的数据通过 usingJobData 方法直接放入,mapper 这种类型数据手动 put 进去:
1 |
|
在 job 的执行过程中,可以从 JobDataMap 中取出数据,如下示例:
1 | public class MajorJob implements Job { |
这个方案相对简单,但在持久化中会遇到 mapper 的序列化问题:
1 | java.io.NotSerializableException: Unable to serialize JobDataMap for insertion into database because the value of property 'personMapper' is not serializable: org.mybatis.spring.SqlSessionTemplate |
方案二:静态工具类
- 创建工具类 SpringContextJobUtil,实现 ApplicationContextAware 接口
1 |
|
- mapper 类上打上 @Service 注解,并赋予其 name:
1 |
|
- Job 中通过 SpringContextJobUtil 的 getBean 获取 mapper 的 bean:
1 | public class MajorJob implements Job { |
推荐使用这个方法。
Quartz 的持久化
定时任务的诸多要素,如任务名称、数量、状态、运行频率、运行时间等,是要存储起来的。JobStore,就是用来存储任务和触发器相关的信息的。
Quartz 中有两种存储任务的方式,一种在在内存(RAMJobStore),一种是在数据库(JDBCJobStore)。
Quartz 默认的 JobStore 是 RAMJobstore,也就是把任务和触发器信息运行的信息存储在内存中,用到了 HashMap、TreeSet、HashSet 等等数据结构,如果程序崩溃或重启,所有存储在内存中的数据都会丢失。所以我们需要把这些数据持久化到磁盘(数据库存储方式)。
实现 Quartz 的持久化并不困难,按下列步骤操作即可:
1. 添加相关依赖:
1 | <!--Quartz 使用的连接池 --> |
2. 编写配置:
1 | /** |
3. 创建 quartz.properties 配置文件
1 | # 实例化ThreadPool时,使用的线程类为SimpleThreadPool |
4. 创建 Quartz 持久化数据的表
数据表初始化 sql 放置在 External Libraries 的 org/quartz/impl/jdbcjobstore 中,直接用其初始化相关表即可。要注意的是,用来放置这些表的库要与 quartz.properties 的库一致。
1 | # |